

As we get close to the 2-year mark since the launch of ChatGPT, it's becoming clearer that LLMs have become a very core part of our lives. The most prominent value add of LLMs has been to bridge the gap between non-technical users and tech applications.
One such problem that we’ve spent the last year working on is enabling business teams to make the right decisions at the right time using their data. The goal is to help them access large amounts of data, find patterns, create narratives, and come up with actionable insights on their own.
Like most teams tackling this problem, we chose the Text-to-SQL approach. Here’s how it works:
Step 1: Creating a Semantic Layer
Most databases are named in ways that make it impossible, even for an expert data analyst to come up with an accurate SQL query, it’s impractical for LLMs to start working without the right context.
So we started by helping data teams create a semantic nomenclature on top that catalogs all their data systems and helps the LLM understand how data is stored.
Step 2: Decoding User Intent
Users tend to ask vague questions like “What is the best-performing channel?”. To decode what the user means by “best performing”, either the LLMs need to make an assumption or clarify.
We did a mix of both. When Crux is unable to make a confident assumption, it asks you a clarifying question and remembers your response for future conversations.
Step 3: Generating an Optimised SQL query
Generating the SQL query is a combination of understanding the user’s question + using the internal knowledge repository with definitions, preferences, and tribal knowledge + the semantic information about how data is stored. This process is then coupled with a tester agent that verifies the logic and the query itself.
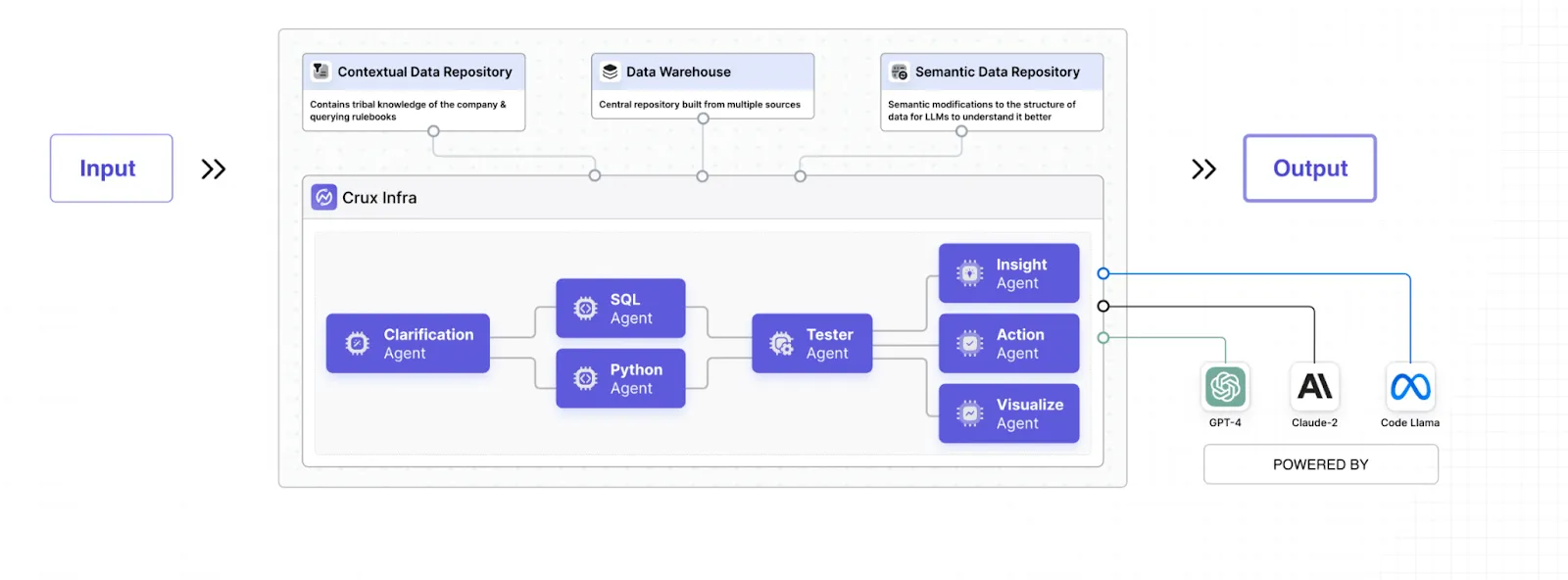
When working with larger teams, the level of optimization of the SQL query also plays a huge role in the performance.
Well, this seemed like a great approach that got us the buy-in from several data and product teams. However, the real challenge presented itself when user feedback started coming in.
And it was harsh!
We learned about a few core issues with this system:
1. Users hate to wait!
“If ChatGPT can answer in a second, why can’t you?”
Generating optimized executable queries and fetching their data typically took 30-120s which is just not good enough for most users
2. Users hate wrong answers EVEN MORE!
Increasing the accuracy beyond 90% requires fine-tuning on organization-specific database structures, which is time-consuming and not every company can make the investment
3. Users are not looking for JUST data
They’re looking for a story, a narrative, a pattern, something actionable.
Text-to-SQL only solves data access, but what next? Figuring out the actionable insight is at least as hard as fetching data if not harder. And that’s still unsolved.
4. You don’t need to query an entire data warehouse to find the answer
Most users have 7-8 fixed use cases that cover their scope of work. 70% of data is outdated and unnecessary for these analyses and can be left out.
We knew we had to change our approach. So we got back to the drawing board!
We realised that to answer specific questions, we only need a subset of data, and identifying this subset doesn't require a powerful SQL querying system.
Here’s what we did:
1. Looked at all the questions that were asked on Crux and classified them into certain buckets depending on what data was needed to answer them. Each of these buckets became a data template
2. Now that we knew what data was needed to answer those questions, we could pre-write the SQL queries with 100% accuracy and cached data from the data warehouses in these formats. This solved both problems - accuracy and latency
3. The next step was to find a way to pick the right data template based on the user’s question. So we built an LLM-based filtering agent that uses RAG to pick the right template.
There would still be edge cases when a predefined data template would not be enough to answer a question. In that case, we would still go back to the previous system to generate a SQL on-the-fly.

This shift allowed us to reduce latency from 30-120s down to 5-20s while improving the quality and accuracy of the results.
But this is easier said than done. We’re now focused on tackling the following challenges:
1. Reducing Latency Further: Aiming to bring the latency down to <10 secs in 90% of cases
2. Scaling Data Caching: Expanding caching strategies to accommodate multiple use cases without compromising performance
3. Advancing Filtering Techniques: Developing more sophisticated LLM agents and utilizing (RAG) for enhanced data filtering
If this sounds like an area you're passionate about, we’d love to have you join our team. We're expanding and looking for passionate professionals to join us:
- Frontend Lead: 4+ yrs of exp in React and TypeScript
- Backend Lead: 4+ yrs of exp in Django, FastAPI, or Spring
If you're interested in tackling these exciting challenges with us, please reach out at [email protected]



